
技术、资本与人才的三角博弈
历史重演
人类科技的新大陆
15世纪中叶以前,欧洲和东方的商路有三条。三条商路都汇聚到地中海东部的欧亚大陆连接点,东方的商品运到此处再转运到欧洲。但15世纪中叶,亚欧商路被奥斯曼土耳其帝国彻底控制。土耳其人对路过商品被收以重税,欧洲人渴望找到通往东方财富的新航道。
在积累了足够的地理知识和航海技术后,1492年哥伦布启程探索通往亚洲的新航道,却意外发现了美洲新大陆。
随着AI技术的飞速发展,人类历史再一次重演。
这次的区别在于,人们已经事先知道远方的新大陆是什么——AGI(通用人工智能)。为了实现AGI的美好愿景,东西方都在组建自己的舰队,去巡航、探索和发现。
很难说谁会成为那个找到新大陆的哥伦布,但可以确定的是——这是一个变革的时代,AGI的实现将彻底改变社会、经济和个人的生活。比如AI自主分析患者基因数据、病史和环境因素,执行超越人类精度的手术操作;只要对着智能硬件说一句话,AI就能策划一场旅行,完成所有线路规划和机酒预定工作……
今年年初,OpenAI创始人奥特曼在社媒平台发表了意味深长的“六字箴言”:near the singularity;unclear which side(奇点临近;不知身处何方)。
通往人类新文明的大航海已经开启,而技术是突破奇点的核心驱动力。
AGI是底层技术的攀登终点
模型能力决定应用上限
寻找AGI的地图,与此前互联网的核心路径有所不同。互联网时代以应用为驱动,并通过烧钱获取流量。然而DeepSeek春节爆火的故事证明,现阶段的AI演进不由应用和流量驱动,而是由底层技术驱动。因此未来AI应用产品形态的定义,和移动互联网时代有不同的逻辑,模型的性能起到决定性作用。这意味着判断谁更有希望冲击AGI,要看谁的基础模型研发能力更强。
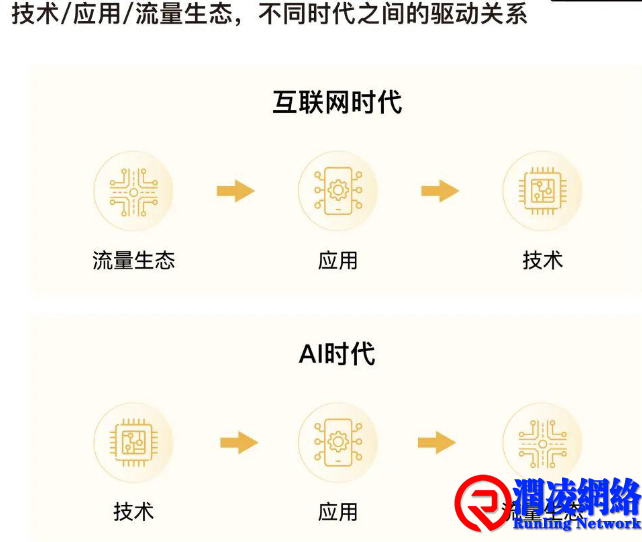
很多人说今年是AI应用元年,然而我们看到现在的应用还不是AI Native形态,也未能动摇现有的互联网Super App(超级应用),原因就在于基础大模型还不够智能。
这一次AI革命,模型能力将决定应用的上限。一切应用都绕不开基础模型的能力边界,当下行业的重点,仍然是基础大模型如何进一步提升智能。
要提升模型智能,需要极大的资源投入。黄仁勋在2025年GTC(GPU 技术大会)上分享后续的AI计算规模,指出Agentic AI进行推理之时所需算力资源,会轻易超过当前的100倍。正因为这样,东西方最强大的国家都在以战略性的姿态布局大模型的基础设施。
从“六小虎”到
新基模五强
自2022年生成式浪潮爆发至今,随着基础模型投入加大,竞争收敛,基模第一梯队的玩家已经越来越集中。在硅谷,基础模型竞争第一梯队逐步收敛到五家公司,它们不断升级投入,科技巨头与创业团队在大模型技术上齐头创新、交叉演进。其中OpenAI靠技术领跑行业,由OpenAI前员工创立的Anthropic紧随其后。Google和Meta两家科技大厂财大气粗,占尽资金和人才优势,X.ai凭借超大投入及Grok模型的性能成功跻身第一梯队。

而在大洋另一边的中国,第一阶段的“百模大战”也已成过去。黄仁勋在2025年的GTC上表示,中国在AI竞赛中已逼近美国,这场长期竞争将会建立更大规模的基础设施。今年,在DeepSeek率先突破推理模型之后,中国的基础大模型格局发生了快速变化。曾被行业热议的“大模型六小虎”——月之暗面、阶跃星辰、智谱华章、MiniMax、百川智能、零一万物之中,已有多家不再训练基模。且发展路线出现分化,百川进入医疗垂直赛道,零一走向应用开发路线,月之暗面、MiniMax则孵化出不同场景的头部应用。
国内仍以AGI作为目标、并持续投入基模的公司已彻底收敛。“六小虎”已成为过去,而新的格局与美国很类似
第一类是战略投入大模型的传统互联网巨头,包括阿里和字节,它们是已知大陆上的旧帝国,想要守住巨大的疆域必须发展新的科技;
第二类是DeepSeek、阶跃星辰、智谱这样的AI创业公司,它们不是旧地图上的中心国家,却代表着探索新大陆的核心力量。
这五家公司,形成了国内的“新基模五强”。

中国市场里为什么是这五家在牌桌上?答案很简单,有钱又有人。钱就不用多说了,训练大模型是明牌重注。要么像字节、阿里、DeepSeek这种自家有粮,要么像阶跃星辰、智谱这样的国家队投入。更重要的是,在此基础上能有高密度的人才,能带领团队做到模型全覆盖且在第一梯队,或者在某一方面遥遥领先。没有这些条件的,一律会在现有模型的基础上做应用研发。
中国基模五强各有各的侧重,看懂这几家各自的优势,才算是看懂中国基模市场的走向,以及中美大航海中我们的实力。
先说互联网大厂。字节是巨型航母,张一鸣亲自带队,人才密度高,综合实力强。同时字节还坐拥抖音、头条等全生态超级应用带来的数据宝藏,2025年将拨出超过1500亿元人民币的战略支出,模型技术和应用多方向全面布局,整体生态非常强。
阿里是开源最早、最完整的大公司,开源生态让它在世界范围内拥有自己的技术品牌。同时阿里在AI的投入上也最坚决,坐拥早期布局的AI基础设施,阿里近3年在AI战略上已经投入3800亿元人民币。现在阿里也已经找到了自己的节奏,从投资AI,到自己做通义千问、夸克,全方位发力,其中千问在开源领域被海外评价为全球前三。
大厂如腾讯,此前并没有像字节和阿里一般大举投入基模。对于腾讯这个坚不可摧的入口级公司来说,可能当下并不是它投入模型的时机,反而是借开源模型探索应用的窗口。
除了互联网大厂,还有梁文锋这样有钱有理想的选手,以一己之力直接掀翻了大模型牌桌。DeepSeek聚焦语言模型,在推理范式上率先突破,同时持续在芯片架构上优化训练算法,成为了全球大模型算法创新的榜样。这几个月对它的分析太多了,在这里就不过多介绍了。
《麻省理工科技评论》曾发文指出,在DeepSeek之外,中国另有四家AI创业公司,同样拥有不俗技术实力与全球竞争力。其中两家基础模型公司阶跃星辰和智谱AI,不但有不错的技术能力,还有一层特殊背景——获政府资金支持,有“大模型国家队”之称。
智谱作为国产大模型六小虎里的成员,能在新的周期继续留在牌桌上,不是没有道理。智谱属于清华系,同时拥有学院派技术实力和密集的资本运作节奏,是中国首个开启IPO的大模型创业公司。智谱的模型布局比较全面,采取政府先行到产业渗透的思路。它和国家政企合作比较多,很可能成为国产大模型第一股。
另一个国家队成员,是相对低调但实力能打的阶跃星辰。根据媒体报道,4月份总书记来上海考察,向总书记重点汇报基础大模型技术和应用最新进展的企业,就是阶跃星辰。阶跃星辰是五强里亮相最晚、也最神秘的一家。背后有上海押宝,是基础大模型布局最完整的公司之一,因为多模态实力强大,在业内被称为“多模态卷王”。
阶跃星辰创始人姜大昕在五月份的采访中有较为详细的技术路线输出:这家公司从诞生起就有非常清晰的AGI技术路线,目前正在加速攻坚视觉领域的核心难题——多模态的理解生成一体化。
随着语言大模型进入发展的平滑期,阶跃星辰重点发力的多模态也被认为迎来陡峭的增长曲线。Meta首席AI科学家杨立昆在前两个月的演讲中提出,当前的大语言模型最终都会被迭代,直指通过多模态进入物理世界、建立世界模型才是未来人工智能的核心方向。
大模型的下个赛点
多模态的理解生成一体化
为什么AGI的实现绕不开多模态?这个问题可以借助Agent阶段的技术需求来理解。
Agent是实现AGI的一个重要发展阶段,它可以通过自主决策、使用工具、调用软件、规划任务等能力,独立帮人类完成具体动作。2025年,AI行业对Agent这一应用形态抱有极大的共识。前段时间火出圈的Manus就是通用型AI Agent,但因为基础大模型中的多模态和推理能力都处于早期,现在的Agent还不是完成态。
完成态的Agent可以无限接近于人的分析、推理,和人的交流、执行。并且它可以结合硬件形态,与物理世界进行交互、完成任务。

在这里我们看到,未来人工智能为人类执行任务,需要拥有面对现实世界的全面感官认知。
基于文本的推理是DeepSeek的强项,但在真实世界完成任务,需要更多基于多模态的推理。比如认准出门的路线、读懂手机屏幕、看懂一张财务报表。
多模态就相当于AGI的感官。在人类日常接触的信息中,文本信息只占30%以内,70%-80%的信息是多模态信息。这意味着,只有实现多模态理解与生成一体化,大模型才能探索物理世界,建立世界模型。正因为此,多模态的突破是AGI的必经之路。
从今年3月开始,字节、阿里和阶跃在多模态方面进展频繁,各公司都在发布新的版本,多模态进入了陡峭的发展期。多模态大模型,正在等待自己的GPT-4时刻。
那么,对于AI相关企业来说,未来的格局可能是什么样?独立的模型厂商往往更有生态优势跟行业伙伴合作,赋能产业,成为基础设施水电煤。例如智能硬件领域机器人、手机、汽车、IoT厂商普遍与阶跃合作。未来几年的格局,大概率是基础模型厂和硬件厂商、云厂商合作,形成一个新的生态;而互联网大厂则会拥有自己的软硬件布局。
尾声
就在这几天,黄仁勋在Hill and Valley(国会山与硅谷)论坛上,回答大国之间AI竞赛的问题时发出警告:AI是一场无限竞争游戏,美国无法通过出口管制取得胜利。
在同一个听证会上,OpenAI的奥特曼(Sam Altman),AMD的苏姿丰(Lisa Su),以及微软的史密斯(Brad Smith),都表达了类似的观点。强调相对中国的进步,目前美国在AI领域没有明显竞争优势。奥特曼在听证会上辩称“很难说我们(比中国)领先多少,时间差不多”。而仅仅是两年前,奥特曼的视线中还没有中国。当时的他也不相信中国大模型会如此逼近硅谷。
四个月前,当DeepSeek登顶中美AppStore,纽约大学教授马库斯曾预判:全球AI争霸赛已经结束了,中美占成平局。4个月后回头看马库斯的观点,他这句话说得为时尚早。
语言模型的发展进入了平滑期,但多模态的GPT-4时刻还远没有到来。在这一意义上,我们还有下一个更值得期待的“赛点”。而在这场竞赛中,中国的大模型厂商已经蓄势待发。
某种程度上,当智能突破奇点,其所开启的无法预知的格局,将不再以任何一人、一国的意志为转移。这会将人类历史推到一个无法预测的进程中。
转载保留链接!网址:http://blog.ividc.com/post/1195.html
1.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;2.作者投稿可能会经我们编辑修改或补充。















